2 minutes
Custom PyTorch Collate Function
If your Dataset class looks something like
class MyDataset(Dataset):
# ... boilerplate ...
def __getitem__(self, idx):
item = self.data[idx]
return item['anchor'], item['positive'], item['negative']
your collate function should be
def collate_fn(data):
anchors, pos, neg = zip(*data)
anchors = tokenizer(anchors, return_tensors="pt", padding=True)
pos = tokenizer(pos, return_tensors="pt", padding=True)
neg = tokenizer(neg, return_tensors="pt", padding=True)
return anchors, pos, neg
and you can use it like
dataset = MyDataset()
dataloader = DataLoader(dataset,
batch_size=4,
shuffle=True,
pin_memory=True,
collate_fn=collate_fn)
for anchors, positives, negatives in dataloader:
anchors = anchors.to(device)
positives = positives.to(device)
negatives = negatives.to(device)
# do more stuff
How does the collate_fn work?
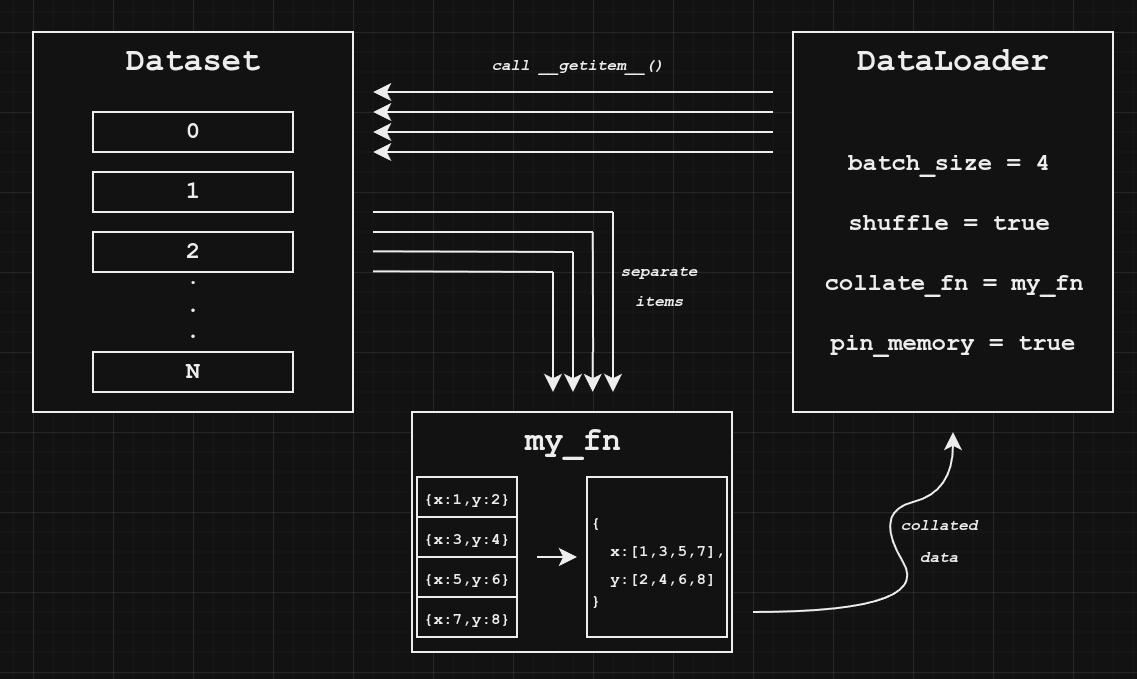
The PyTorch collate function accepts a list of results from calls to the dataset getitem function and combines their components into tensors for convenient training.
Under the hood, your DataLoader is making multiple calls to dataset.__getitem__(), one for each item in batch_size. Usually it is smart enough to know how to combine them into a tensor for training (here is the default collate function), but sometimes you need custom logic.
Technically you don’t need a collate function. You could collate within the training loop. But besides cluttering up your training loop, you won’t be able to take advantage of multithreaded processing (num_workers > 1), so your collation logic will block your training code.
What about pin_memory?
The pin_memory parameter specifies whether we should create the tensors in pinned RAM or not. This avoids some additional overhead when copying data to the GPU.
A common misconception is that this is pinning the GPU VRAM. Actually, this pins the RAM, not the VRAM.
If we check the Nvidia technical blog they give the following four recommendations (summarized):
- Minimize back and forth data transfers between RAM and GPU. Even if code is no faster on the GPU, it may be worth executing there to avoid the round-trip transfer cost, which is relatively slow.
- Use page-locked (“pinned”) memory when possible. By default, your machine uses pageable memory which means the physical address of RAM can change. When transferring data to the GPU, CUDA first needs to copy it to a fixed “pinned” address to be copied over. In your DataLoader, if you specify
pin_memory=True, the tensors will automatically be created in pinned memory, avoiding the pageable memory -> pinned memory copy. - Combine multiple small transfers into a large transfer to avoid overhead.
- Data transfers can be executed asynchronously. In PyTorch that looks like
tensor.to(device, non_blocking=False).