3 minutes
Paper Summary: Defending Against Neural Fake News
Defending Against Neural Fake News by Zellers et al. presents a model for controllable text generation called Grover. This model can be used to create highly believable computer-generated news articles. The authors present this paper as a method of detecting and preventing the spread of fake news. They claim their model is 92% accurate at detecting fake news stories, partially due to artifacts that generators include in the generated text.
Grover functions in an adversarial manner:
- an “adversary” generates synthetic stories
- a “discriminator” identifies fake stories
Current generative models are fairly good at creating realistic-looking text, but largely lack the ability to be controlled via tunable parameters. In contrast, Grover models news stories as distributions like (domain, date, authors, headline, body) to be sampled from. Adversaries specify domain, date, and headline, and the generator creates the body and author as well as a more appropriate headline.

Grover samples from a joint distribution of the parts of a news article.
Grover is built using a transformer architecture similar to BERT and GPT. Depending on the model size, the number of parameters varies from similar to GPT to on par with GPT-2. The authors use the RealNews corpus, resulting in 120 gigabytes of total file size. Training took 2 weeks on 256 TPU v3 cores.
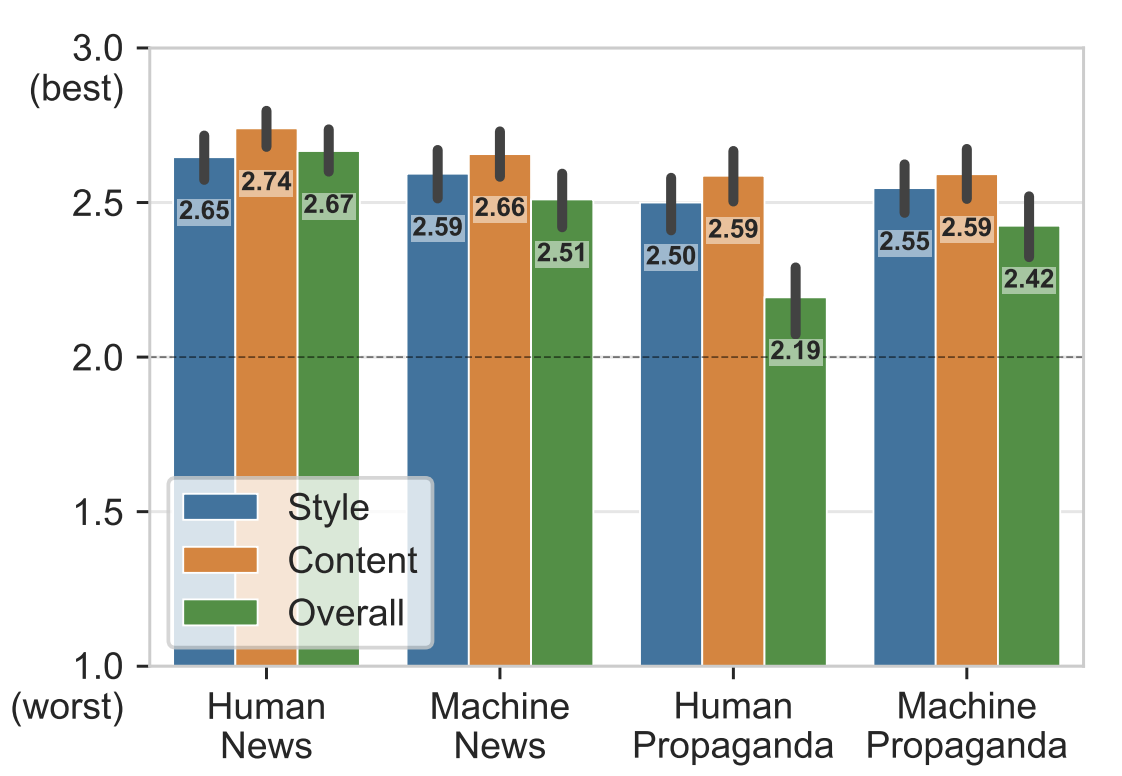
Grover is actually better at writing synthetic articles than humans are according to authors.
The results of the authors’ subjective experiments show that humans have a hard time identifying Grover-written propaganda. Using Mechanical Turk, articles were rated according to stylistic consistency, content sensibility, and overall trustworthiness. Grover, on the other hand, turns out to be a fairly good discriminator.
The authors also tested GPT2, BERT, and FastText on the task of classifying news as human or synthetic. The researchers set up the experiment in an unpaired setting (give a human/synthetic classification for a single article) and a paired setting (determine which is the human and which is the synthetic between 2 articles). Unsurprisingly, the paired setting was far easier. Also unsurprisingly, the larger models perform better at discriminating when paired with smaller generators.
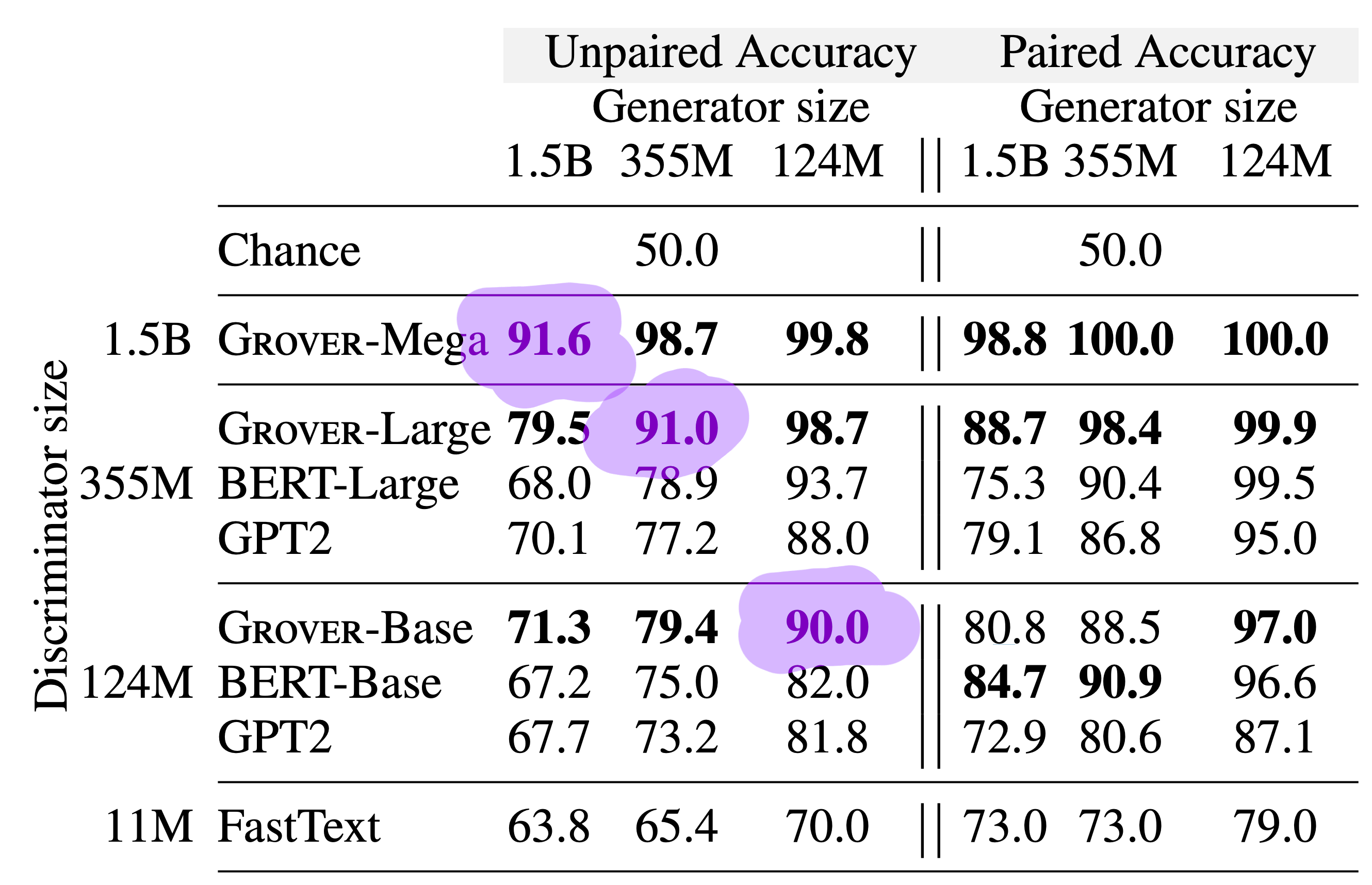
For generators of the same size, discrimination accuracy was around 90-91%.
When comparing generator/discriminator pairs with the same numbers of parameters, classification accuracy was around 90-92%. Grover tends to leave artifacts when generating text, and this fact may be part of the reason discriminators are so good at identifying synthetic text. For one, the authors identify “exposure bias” as one of the reasons. The fact that Grover is never trained on generated text, only on human-authored articles seems to contribute to this. Perplexity also tends to vary over the length of the generated article, and depending on the sampling variance may fall out of the distribution of human language.