4 minutes
What Are Attention Masks?
TLDR: Attention masks allow us to send a batch into the transformer even when the examples in the batch have varying lengths. We do this by padding all sequences to the same length, then using the “attention_mask” tensor to identify which tokens are padding.
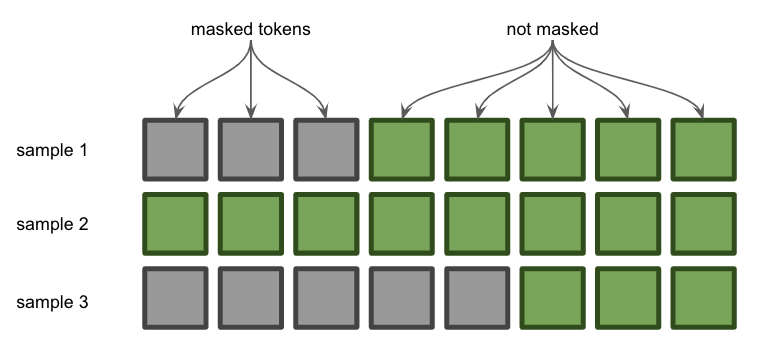
Here we use a batch with three samples padded from the left since we want to predict the next token on the right. (Padding on the right would probably predict another pad.)
If you want to perform inference with transformers one sequence at a time, you can ignore attention masks. The “slow way” will be sufficient for your needs.
The slow way
We can perform inference with GPT-2 using sequences one at a time, but it’s slow:
from transformers import GPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
gpt2 = GPT2LMHeadModel.from_pretrained('gpt2')
context = tokenizer('It will rain in the', return_tensors='pt')
prediction = gpt2.generate(**context, max_length=10)
tokenizer.decode(prediction[0])
# prints 'It will rain in the morning, and the rain'
It’s way faster to batch the inputs, which means adding their token vectors to the context and performing inference only once.
The un-slow way
The cool way to perform inference on many samples is with batching. It’s much faster but it’s also slightly more complicated.
tokenizer.padding_side = "left"
tokenizer.pad_token = tokenizer.eos_token
sentences = ["It will rain in the",
"I want to eat a big bowl of",
"My dog is"]
inputs = tokenizer(sentences, return_tensors="pt", padding=True)
output_sequences = gpt2.generate(**inputs)
for seq in output_sequences:
print(tokenizer.decode(seq))
What’s happening here? And what does this have to do with attention masks? First let’s explain padding, then take a look at the code line by line.
We feed tokens into transformer-based language models like GPT-2 and BERT for inference as tensors. A tensor is like a python list but with a few extra features and restrictions. Specifically, for a tensor of dimension 2+, all vectors in that dimension need to be the same length. For example,
from torch import tensor
tensor([[1,2], [3,4]]) # ok
tensor([[1,2], [3]]) # error!
When we tokenize an input, it it will be turned into a tensor containing sequence of integers, each corresponding to an item in the transformer’s vocabulary. Here is an example tokenization in GPT-2:
| String | Token ID |
|---|---|
| It | 1026 |
| will | 481 |
| rain | 6290 |
| in | 287 |
| the | 262 |
Suppose we wanted to include a second sequence in our input:
| String | Token ID |
|---|---|
| My | 3666 |
| dog | 3290 |
| is | 318 |
Because these two sequences have different lengths, we can’t just combine them in one tensor. Instead, we have to pad the shorter sequences with dummy tokens so that each sequence is the same length. And because we want the model to continue to add to the right side of our sequence, we will pad the left side of shorter sequences.
| String | Token ID |
|---|---|
<pad> |
50256 |
| My | 3666 |
| dog | 3290 |
| is | 318 |
This is where the attention mask comes in. The attention mask simply shows the transformer which tokens are padding, placing 0s in the positions of padding tokens and 1s in the positions of actual tokens. Now that we understand that, let’s look at the code line by line.
tokenizer.padding_side = "left"
This line tells the tokenizer to begin padding from the left (default is right) because the logits of the rightmost token will be used to predict future tokens.
tokenizer.pad_token = tokenizer.eos_token
This line specifies which token we will use for padding. It doesn’t matter which one you choose, but here we’re choosing the “end of sequence” token.
sentences = ["It will rain in the",
"I want to eat a big bowl of",
"My dog is"]
These three sequences all have different lengths when tokenized, so should be a good test of our padding method.
inputs = tokenizer(sentences, return_tensors="pt", padding=True)
Now we tokenize. We’re passing in the sentences from above, telling the tokenizer to use PyTorch tensors (rather than Tensorflow), and telling the tokenizer to add padding for us. We can print inputs here to confirm that, yes, tokenization is working as we thought:
{'input_ids': tensor([
[50256, 50256, 50256, 1026, 481, 6290, 287, 262],
[ 40, 765, 284, 4483, 257, 1263, 9396, 286],
[50256, 50256, 50256, 50256, 50256, 3666, 3290, 318]
]),
'attention_mask': tensor([
[0, 0, 0, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 1, 1, 1]
])}
As you can see, the first and third sequence include padding at the beginning, and the attention_mask parameter marks the position of this padding.
Now let’s actually pass this input into the model to generate new text:
output_sequences = gpt2.generate(**inputs)
If you’re unfamiliar with **kwargs syntax for function calls, this passes in the inputs dict as named parameters, using the keys as the parameter names and the values as the corresponding argument values. Check the docs for more info.
Finally, we just need to loop through each of the generated sequences and print out the result in human readable form, using the decode() function to convert token IDs to strings.
for seq in output_sequences:
print(tokenizer.decode(seq))