4 minutes
A Few Notes on the Transformer
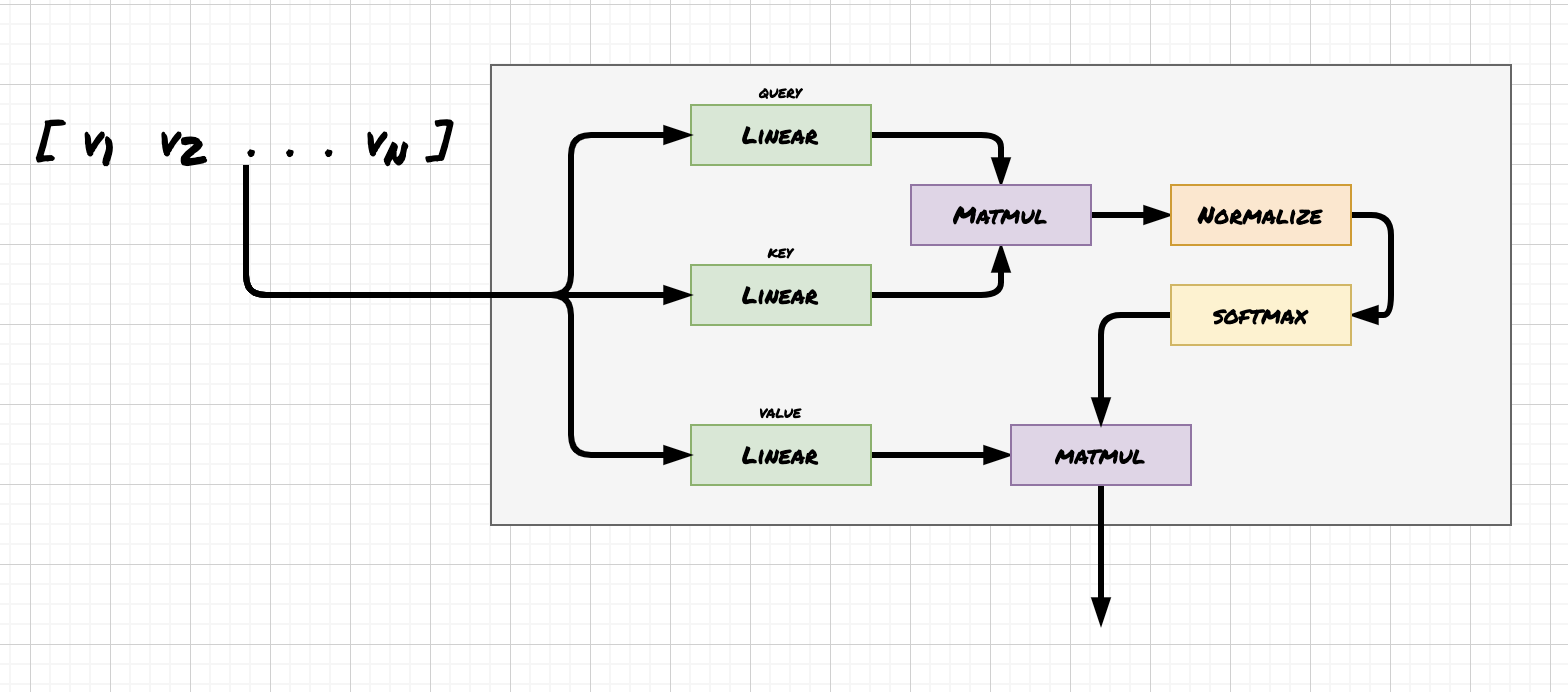
A self-attention block depicted as a neural network.
In this post I will describe the attention mechanism, commonly used in transformers, a popular neural language architecture. Most of the most well-known large language models of late are based on the transformer architecture. Attention was first described in Attention is All You Need by Vaswani et al.
What is attention?
At a high level, attention is a mechanism for neural networks to boost portions of an input which are relevant and ignore those which aren’t. In language models, attention is used as a way for the model to learn which portions of a sentence are relevant to each word.
What is attention for?
Let’s use an example:
I am sitting at the library with my friend.
It should be pretty clear that not all words in this sentence are equally important. What words are relevant to “I”? Probably “sitting”, “library”, and “friend”. Likewise, “the” might only be relevant to “library”. Attention provides a way for a model to increase and decrease the importance of each word.
Since the value of each token in the sequence is dependent on other tokens, this method of generating word embeddings is very different from more classical methods like Word2Vec and GloVe. There is no one fixed vector for a given word.
And this makes sense. Many words in English are homonyms, and have identical spellings for distinct meanings. For example, “rock” is a genre of music but also can mean a stone. The word “run” has 645 meanings and has recently replaced “set” as the word with the most definitions. It would not make sense for all of these homonyms to have the same vector.
An interactive example
You can hover over each word to see the relative importances of each word in the sentence to the hovered word.
How does self-attention work?
The Vaswani paper describes scaled dot product attention, which involves normalizing by the square root of the input dimension.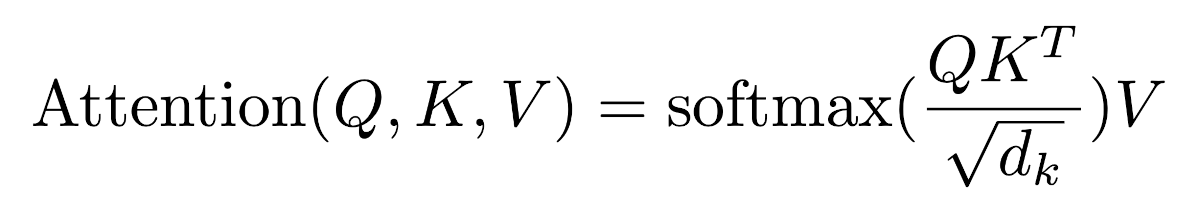
In linear algebra terms this means multiplying the 1xd input vector by a matrix of size dxd. In neural network terms, this means passing the input vector through a full-connected layer. After Mk and Mq are multiplied, they are normalized by the square root of dk, a constant representing the dimension of the input vector.
Can we attend to multiple parts of a sentence?
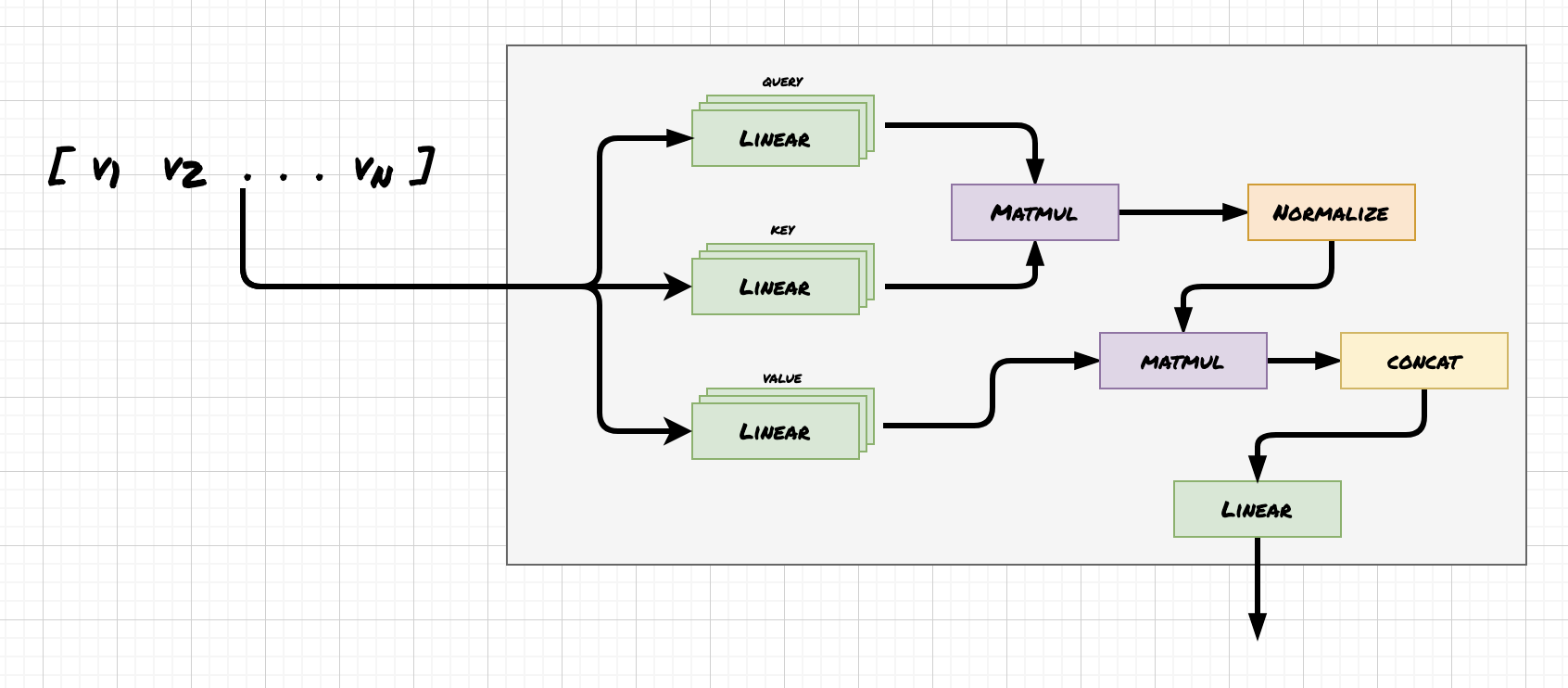
Multi-headed attention means performing attention n times in parallel inside of an encoder block.
Yes, that is called multi-headed attention. Its architecture is very similar, using additional Mk, Mq, and Mv matrices for each additional “attention head”. In the Vaswani paper they used 8 heads.
How do transformers compare with other architectures (e.g. RNN/CNN)?

When the input sequence length n is lower than the input dimensionality d, self-attention is faster than recurrent neural networks. Self-attention is also easily parallelizable.
Generally speaking, RNNs are able to memorize but not parallelize, and CNNs are able to parallelize but not memorize. Transformers are able to do both.
The Vaswani paper outlines three main benefits:
-
Computational complexity per layer. Self-attention layers are faster than recurrent layers when the input sequence length is smaller than the input vector dimensionality.
-
The opportunity to parallelize calculations. Each head in multi-headed attention can be computed separately in an encoder layer.
-
Easier to learn long-range dependencies. For many English sentences, especially fairly complex ones found in more scientific writings, the full context of a word cannot be learned from its immediate neighbors. Sometimes it can’t even be found in the same sentence. However, even though most language models prior to the transformer had theoretically infinite input sequence lengths, in practice it was quite difficult for them to learn long-range dependencies. Because a transformer sees its whole input simultaneously, Vaswani argues, it is able to more easily learn those dependencies.
Is that all?
No. In part two I will describe the encoder and decoder blocks, as well as the self-supervised training process.